
Deno KV internals: building a database for the modern web



Deno is designed to streamline web and cloud development with built-in modern tools, direct access to web platform APIs, and the capability to import modules via npm. Web apps very often require some persistent application state. Setting up a database involves numerous configuration steps and the subsequent integration of an ORM or other systems.
What if you could access such a database without any preliminary setup? This is what Deno KV allows you to do:
const kv = await Deno.openKv();
const userId = crypto.randomUUID();
await kv.set(["users", userId], { userId, name: "Alice" });Why build Deno KV?
The Deno runtime doesn’t just run on your local machine in the form of the
deno executable, but also on our Deno Deploy cloud platform which
allows you to deploy your Deno apps to many regions around the world. This
global deployment minimizes latency between your users and your app’s compute,
which can be a huge performance boost for your app.
We knew that we wanted to build a database for Deno, because of a very simple problem we heard from many customers: unless your app’s data is also globally distributed, you won’t be able to make use the performance benefits you get by distributing your compute.
Additionally, because the Deno runtime is designed to run either locally in a single instance scenario, or globally in a multi-instance scenario, any API we introduce for one of the two scenarios should also work great in the other. This makes it easy to develop and test your app locally, and then deploy it globally without having to change your code or add any configuration.
This led us to a few design goals for Deno KV:
- Scalable: a distributed database that can handle large volumes of data with high throughput
- Highly performant: minimal high latency round-trips between compute and database to minimize impact of network latency
- JavaScript-native: a database that’s designed to be used from JavaScript and TypeScript, with an API that natively uses JavaScript types
- Atomic transactions: a database that provides atomic operations to ensure data integrity and enable complex application logic
- Works seamlessly locally and globally: a database that works great in both single-instance and multi-instance scenarios
So, we set out to build two versions of the Deno KV system, with the same user-facing API. A version of Deno KV for local development and testing, built on SQLite, and a distributed systems version for use in production (especially on Deno Deploy). This post is about the implementation of the production, distributed systems version of Deno KV. If you’re interested in the SQLite implementation of Deno KV, you can read the source code yourself as it is open source.
FoundationDB: scalable, distributed, flexible, and production-ready
We chose to build Deno KV atop of FoundationDB, Apple’s open source distributed database used in iCloud and by Snowflake, since it’s perfect for building scalable database solutions: it’s thoroughly verified with deterministic simulation, scalable and efficient, and provides the transactional key-value storage API.
While FoundationDB provides the necessary mechanisms of a robust distributed database, there’s still several challenges when turning that into a seamless JavaScript-native experience that works within our Deno Deploy platform:
- Deno KV is multi-tenant not only in data but also in configuration. Different users have different replication setups, backup policies, and throughput quotas. FoundationDB does not have native mechanisms to handle this.
- We want Deno KV to be fully JavaScript-native and use JavaScript types. For example, Deno KV can store signed varints (bigint), and we want to support an atomic sum operation on these, but FoundationDB itself does not support atomic sums on varints.
- To minimize potential for unbounded latency between compute and data, the Deno KV API is designed around non-interactive transactions (i.e. atomic operations), while FoundationDB provides optimistic interactive transactions. Even though possible, there is unnecessary overhead when implementing the Deno KV API on top of FoundationDB.
These constraints led us to design a new system ontop of a FoundationDB that we call the “transaction layer”. It performs transaction processing and cross region data repliation in a distributed way, while still delegating the difficult aspects of a distributed database to FoundationDB: sharding, synchronous replication within a cluster, ensuring serializable and linearizable processing of transactions, and storing data durably.
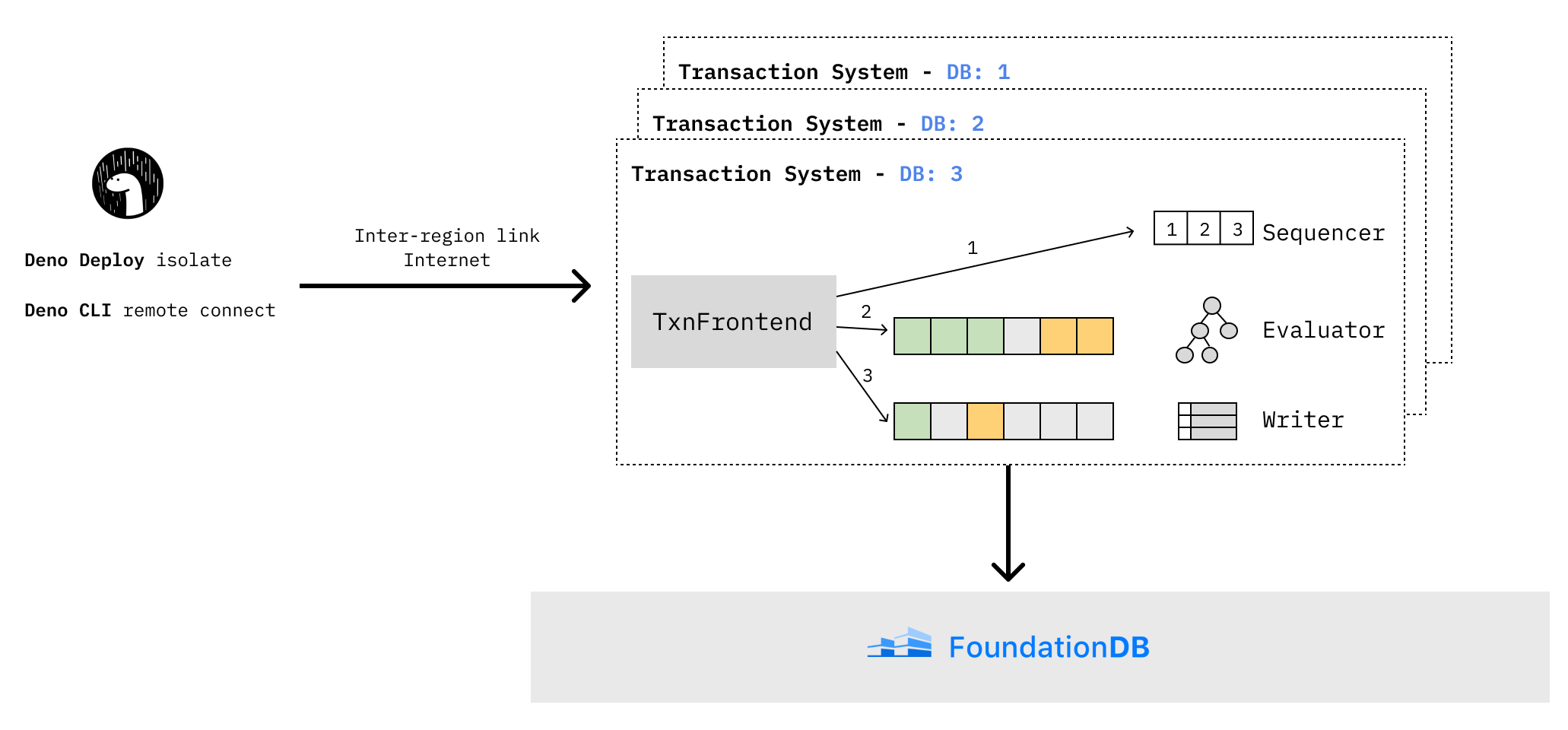
Let’s dive into how we designed our transaction layer for atomicity, minimal latency, and high concurrency.
Atomic operations with minimal network requests
Atomic operations, usually interactive transactions, as in they require multiple requests to the database to guarantee atomicity.

However, for a globally distributed database, interactive transactions are costly. If a write operation requires several trips between the compute server and a database region, then a web app performing multiple write operations could experience high network latency.

To minimize latency, we designed global Deno KV to be non-interactive — all transactions should complete within one or two network trips. We’ve done so by enclosing all atomic writes into a “bag” of conditions, write commands, and conflict-free mutations:
- Condition: to guarantee atomicity, we check the
versionstampof the key. If it’s false at the time the operation is executed, the entire operation is discarded - Write command: any
.set()or.delete()operation on a key - Conflict-free mutation: any function that takes the old value of the key and
returns a new value. For example, the mutation type
.sum()adds the provided operand to the old value
To create this “bag”, Deno KV requires all atomic operations to be chained
following
.atomic():
const kv = await Deno.openKv();
const change = 10;
const bob = await kv.get(["balance", "bob"]);
const liz = await kv.get(["balance", "liz"]);
if (bob.value < change) {
throw "not enough balance";
}
const success = await kv.atomic()
.check(bob, liz) // balances did not change
.set(["balance", "bob"], bob.value - change)
.set(["balance", "liz"], liz.value + change)
.commit();This API design for atomic operations ensures minimal trips between compute and database for optimum performance.
Building on top of FoundationDB’s lock-free system
“Locks” in databases are mechanisms to ensure data integrity. These mechanisms only let one transaction modify or access data. In contrast, a lock-free system allows concurrent processes to access and modify data, providing parallelism and scalability without sacrificing data integrity.
Despite FoundationDB using a lock-free design, simply delegating the conflict-check mechanism to FoundationDB would lead to latency issues, especially if the atomic operation performs a conflict-free mutation that cannot be pushed down to a primitive of the underlying database.
await kv.atomic().sum(["visitor_count"], 1n).commit();To maximize performance and concurrency for atomic operations, we built the Deno KV Transaction Layer that manages the global order of atomic operations. For each transaction that is received by this Transaction Layer:
- The transaction is assigned a Transaction Sequence Number (“TSN”), a monotonic integer whose order is equivalent to the linearized order of atomic operations, by a sequencer
- The transaction is batched with other transactions, from which the evaluator constructs a graph that describes the relations between all conditions, write commands, and conflict-free mutations. The evaluator then processes the graph with maximum concurrency until the value of every graph node is known.
- The transaction is finally committed to FoundationDB by the writer
The sequencer, evaluator, and writer are distinct components that work together to process high volumes of operations. But how do we squeeze out even more performance from this pipeline?
Faster operations with speculative execution
Speculative execution is a technique for maximizing instruction processing throughput where some work is done that might not be needed.
Deno KV’s Transaction Layer uses this technique, where transactions are assigned a global order in a centralized way, but processed out-of-order elsewhere. Outputs of transactions are then used speculatively in future transactions before they are durable on disk. The effect of a transaction is only visible externally after it’s been committed to FoundationDB.
The core data structure of this mechanism is the “Transaction Reorder Buffer”, which manages the flow of transactions to process:
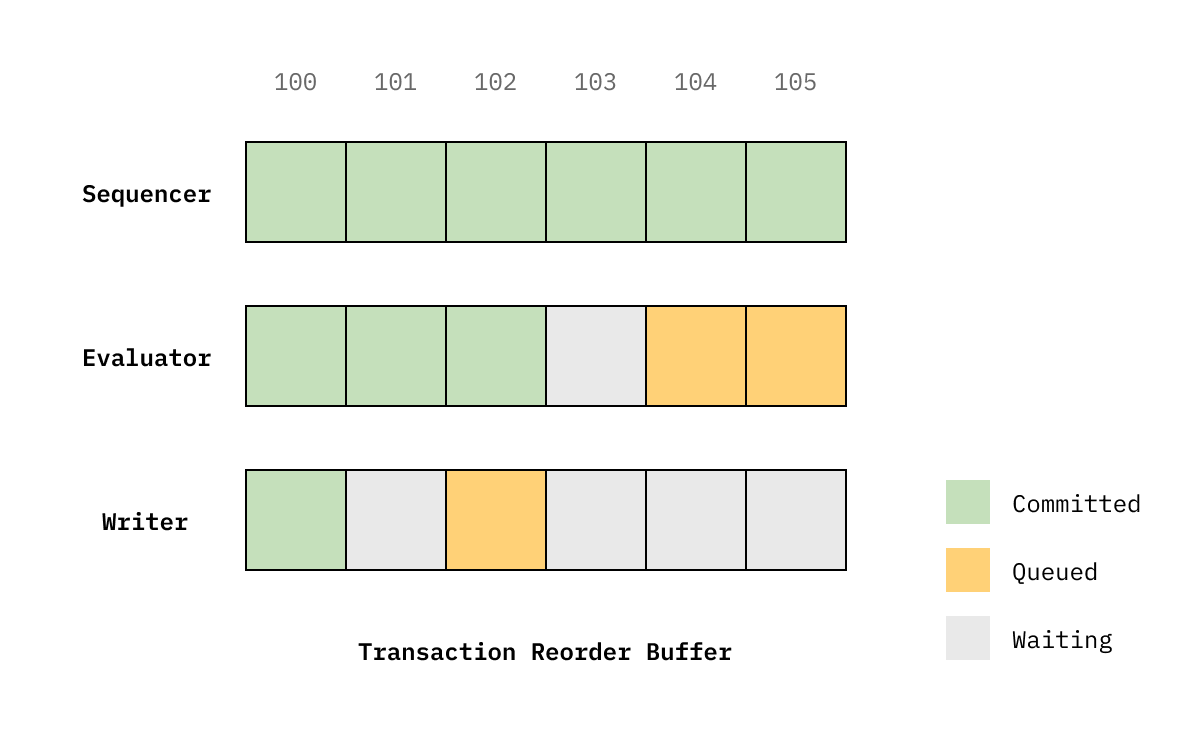
The sequencer is responsible for issuing monotonic integers that are continuous within an epoch. While being a singleton for every KV database, sequencing is a very cheap operation since it’s just an increment on an in-memory atomic counter. The sequencer also only needs to wait for the previous sequencer to be committed (green).
The evaluator processes transactions in batches. In each batch, the evaluator constructs a “data flow subgraph” that describes the relations between all conditions, write commands, and conflict-free mutations. It’s a graph of operations that determine whether the transactions succeed or fail, and the operations final values. The evaluator then processes the subgraph with maximum concurrency until the value of every graph node is known.
To better illustrate this data flow subgraph, which enables high concurrency in a lock-free system, let’s look at an example:
// Client 1 is updating the login of user UID1 from “alice” to “bob”
await kv
.atomic()
.check({ key: ["users", UID1], versionstamp: V1 })
.check({ key: ["user_by_login", "bob"], versionstamp: null })
.set(["users", UID1], user1)
.set(["user_by_login", "bob"], UID1)
.delete(["user_by_login", "alice"])
.commit();
// Client 2 is creating a new user with login "bob"
await kv
.atomic()
.check({ key: ["user_by_login", "bob"], versionstamp: null })
.set(["users", UID2], user2)
.set(["user_by_login", "bob"], UID2)
.commit();These two operations above are mutually conflicting, so only one can succeed. Assuming the second operation is assigned a larger TSN than the first, this would be the data flow subgraph constructed from an evaluator batch containing these two operations:
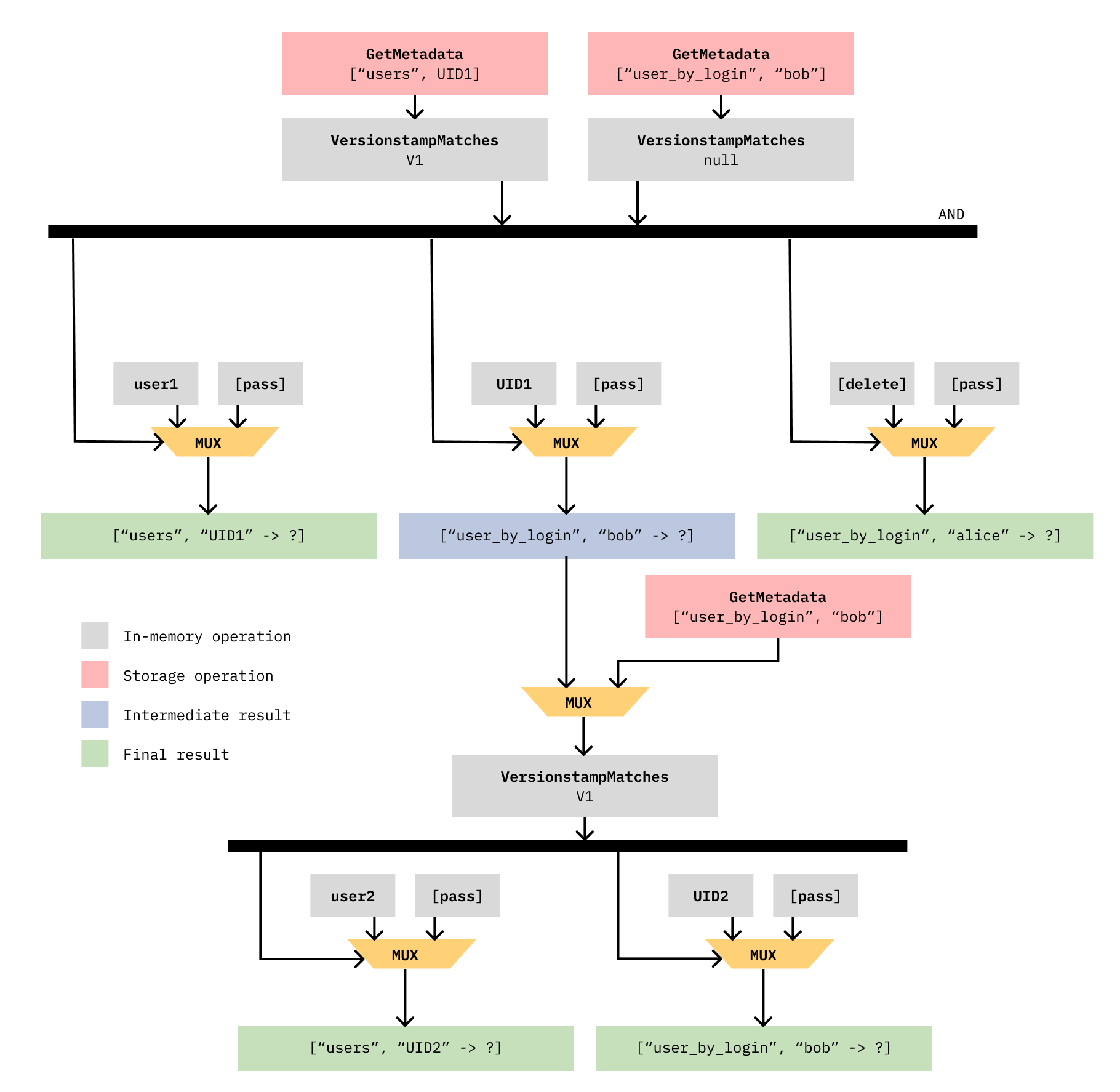
This diagram looks bit complicated - let’s walk through it.
The top row (with the two GetMetadata boxes) represents the two .check()
commands from Client 1 (.check({ key: ["users", UID1], versionstamp: V1 }) and
.check({ key: ["user_by_login", "bob"], versionstamp: null })). They flow into
the horizontal AND line because both checks need to succeed.
The second row from the top (beneath the horizontal AND line) shows three
MUX (aka a
multiplexer logic gate)
operations, which represents Client 1’s .set() and .delete() commands. Above
each MUX gate shows each commands inputs:
.set(["users", UID1], user1)->user1and[pass].set(["users_by_login", "bob"], UID1)->UID1and[pass].delete(["user_by_login", "alice"])->[delete]and[pass]
Note that [pass] simply means keep the old value, since those commands have a
single input when MUX gates can accept two inputs.
While the first and third MUX gate output is green (final result), the middle
one is blue (intermediary result). Keep in mind that final result is not a
value; it’s a write function whose input (represented in the diagram by ?)
will be evaluated after this graph is created.
So why is there an intermediary result? This is because Client 2’s .check()
needs to assert versionstamp on the shared key ["user_by_login", "bob"]. In
order to resolve this intermediary result and get to a final result, we use
another MUX gate that takes the intermediary result and the GetMetadata of
["user_by_login", "bob"].
This takes us to the bottom row, where there are two MUX gates representing
Client 2’s .set() commands (.set(["users", UID2], user2) and
.set(["user_by_login", "bob"], UID2)). From these gates, we can reach final
results.
After the evaluator creates this data flow subgraph from a batch of operations, it calculates the results, and buffers them in memory. These in-memory results are available to use in the next evaluator batches, for more speculative execution, since the results may not yet be visible in FoundationDB. These in-memory results will be discarded as the known committed version advances, or when we know for sure we can read the data from FoundationDB.
Finally, the writer is initiated to persist the mutations. The writer also processes transactions in batches. In each batch, the writer writes the outcome of the transactions to the underlying database, and performs various other tasks, like writing the replication log and queuing up keys for expiration.
Using speculative execution with the sequencer-evaluator-writer pipeline helps maximize concurrency and performance while maintaining data integrity for atomic operations.
Conclusion
The development of Deno KV was informed by the needs of modern web development and the possibilities presented by FoundationDB. Our emphasis has always been on functionality, scalability, and the seamless integration of JavaScript. By leveraging FoundationDB’s lock-free system and introducing features like the transaction layer and speculative execution, we aimed to address both performance and user experience.
However, technology and needs evolve. While we believe in the foundation and principles behind Deno KV, we’re also aware of the continuous advancements in the tech landscape. Our journey with Deno KV is an ongoing one, shaped by both our vision and the invaluable feedback from our user community.
As we look ahead, we are dedicated to refining Deno KV, responding to emerging needs, and ensuring its adaptability in a rapidly evolving web and cloud environment. We welcome all developers to try Deno KV, and more importantly, to share insights and feedback that can guide its future direction.
Signup for Deno Deploy and get access to a zero-config, globally distributed database for free.